プレスリリース
大規模言語モデルで公会計研究の軌跡を追跡 ~40年分の文献をAI解析
問合せ先を一部修正
2025年7月29日初出

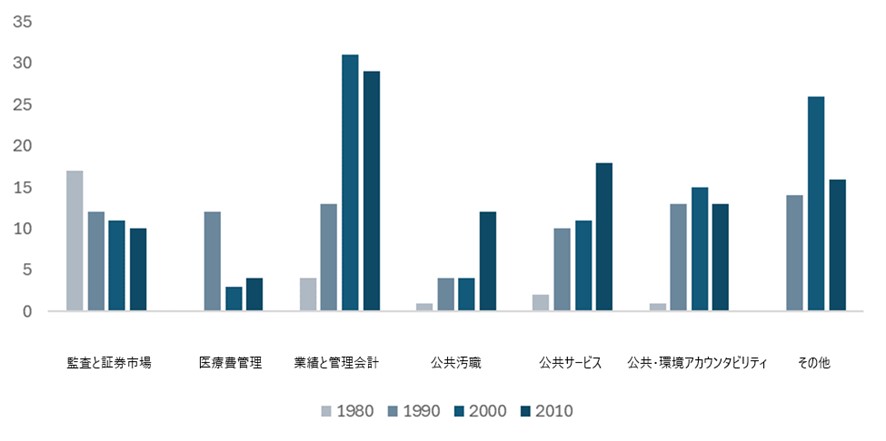
同志社大学 商学部商学科 廣瀬喜貴准教授、横浜市立大学 国際商学部・大学院データサイエンス研究科 黒木 淳教授らの研究グループは、大規模言語モデルBERT*1を用いて、1980~2019年の公会計研究(PSAR)論文306本分のフルテキストを対象として、トピックモデリング手法(BER Topic)を適用し、主要なトピックを抽出しました。従来のLDA*2ではなく、BERTを使ったことで、より文脈に応じた分類が可能となりました。
本研究成果は、アメリカ会計学会セクション雑誌であるJournal of Emerging Technologies in Accounting誌に掲載されました。(2025年7月18日オンライン公開)
研究成果のポイント
- BERTによる文脈理解によって,LDAよりも精度の高い分類を実現した
- 学際的な領域である公会計研究のフルテキストを対象に、7つのトピックを発見した
- 学術領域が多岐にわたる複雑な研究領域に今後応用できる可能性を示唆している
*1 大規模言語モデルBERT:2018年にGoogleにより論文で発表されたNLP(自然言語処理)モデルで、Transformer双方向エンコーダ表現(Bidirectional Encoder Representations from Transformers)の略。深層学習と呼ばれる学習方法のモデルの一種で、過去のNLP(自然言語処理)モデルと異なり、文章を文頭と末尾の双方向から事前学習するように設計されている。また、学習に使用することができるデータが大量に存在し、様々なタスクに対して柔軟な対応が可能という特徴がある。
*2 LDA:Latent Dirichlet Allocation(潜在ディリクレ配分法)とは、膨大なテキストデータから「隠れたテーマ(トピック)」を自動的に発見するための統計的手法で、データがどのトピックをどの程度含んでいるかを確率的に推定する。
| 取材に関するお問い合わせ |
同志社大学 広報部広報課
TEL:075-251-3120 |
|---|
- タグ
- 教育・研究